KDE-Plot-Visualisierung mit Pandas und Seaborn
- Datenvisualisierung mit normalem KDE-Plot und Seaborn in Python
- Eindimensionaler KDE-Plot mit Pandas und Seaborn in Python
- Zweidimensionaler oder bivariater KDE-Plot mit Pandas und Seaborn in Python
- Fazit
KDE ist Kernel Density Estimate, das zur Visualisierung der Wahrscheinlichkeitsdichte von kontinuierlichen und nichtparametrischen Datenvariablen verwendet wird. Wenn Sie die mehreren Verteilungen visualisieren möchten, erzeugt die Funktion KDE eine übersichtlichere Darstellung, die besser interpretierbar ist.
Mit KDE können wir mehrere Datenbeispiele mithilfe eines einzigen Diagrammplots visualisieren, was eine effizientere Methode zur Datenvisualisierung ist.
Seaborn ist eine Python-Bibliothek wie matplotlib. Seaborn kann mit pandas und numpy für Datendarstellungen integriert werden.
Datenwissenschaftler verwenden diese Bibliothek, um informative und schöne statistische Diagramme und Grafiken zu erstellen. Anhand dieser Präsentationen können Sie die klaren Konzepte und den Informationsfluss innerhalb der verschiedenen Module verstehen.
Wir können univariate und bivariate Graphen mit der KDE-Funktion, Seaborn und Pandas zeichnen.
Wir werden etwas über die KDE-Plot-Visualisierung mit Pandas und Seaborn lernen. Dieser Artikel verwendet einige Beispiele des mtcars-Datensatzes, um die KDE-Plot-Visualisierung zu zeigen.
Bevor Sie mit den Details beginnen, müssen Sie die Bibliotheken seaborn und sklearn mit dem Befehl pip installieren oder hinzufügen.
pip install seaborn
pip install sklearn
Datenvisualisierung mit normalem KDE-Plot und Seaborn in Python
Wir können die Daten mit der normalen KDE-Plot-Funktion mit der Seaborn-Bibliothek plotten.
Im folgenden Beispiel haben wir 1000 Datenbeispiele mit der Zufallsbibliothek erstellt und sie dann im Array von numpy angeordnet, da die Seaborn-Bibliothek nur mit numpy und Pandas dataframes gut funktioniert.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
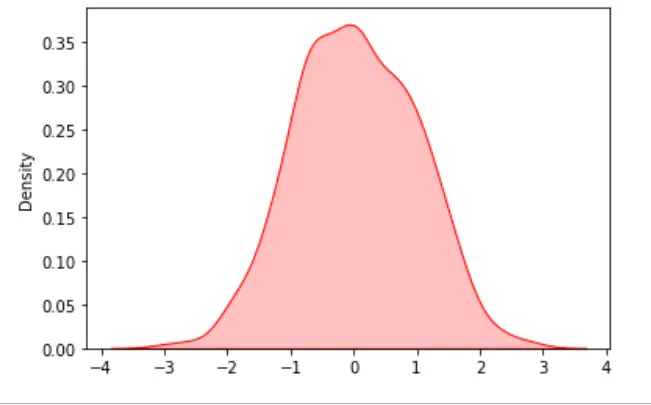
# KDE Plot with seaborn
res = sn.kdeplot(data, color="red", shade="True")
plt.show()
Ausgabe:
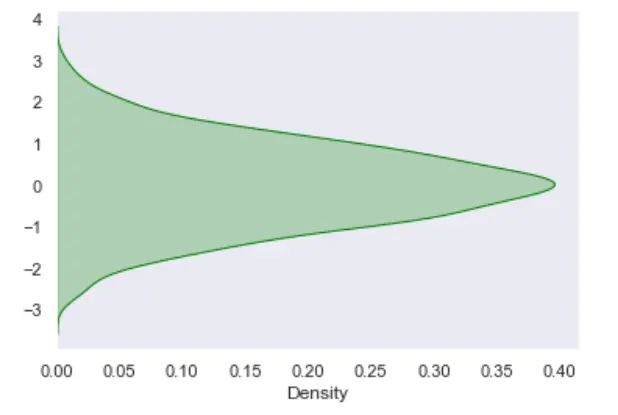
Wir können das obige Datenbeispiel auch vertikal visualisieren oder das obige Diagramm mithilfe der KDE- und Seaborn-Bibliothek umkehren. Wir haben die Plot-Eigenschaft vertical=True verwendet, um den obigen Plot umzukehren.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(1000)
# KDE Plot with seaborn
res = sn.kdeplot(data, color="green", vertical=True, shade="True")
plt.show()
Ausgabe:
Eindimensionaler KDE-Plot mit Pandas und Seaborn in Python
Wir können die Wahrscheinlichkeitsverteilung für ein einzelnes Ziel oder kontinuierliches Attribut mithilfe des KDE-Plots visualisieren. Im folgenden Beispiel haben wir eine CSV-Datei des Datensatzes mtcars gelesen.
Es gibt mehr als 350 Einträge in unserem Datensatz, und wir werden die univariate Verteilung entlang der x-Achse visualisieren.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# read CSV file of dataset using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# kde plot using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
plt.show()
Ausgabe:
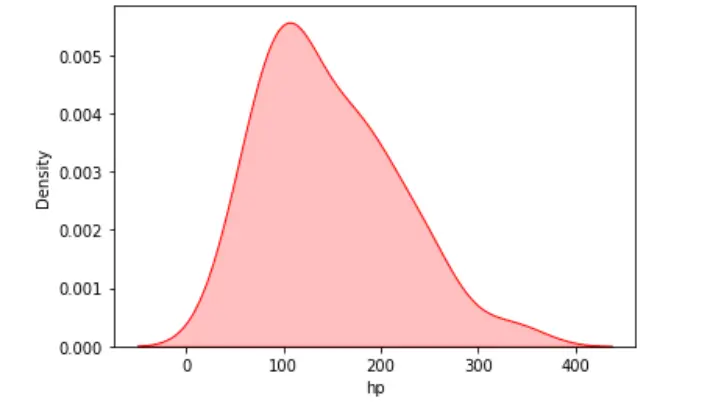
Sie können das Diagramm auch umkehren, indem Sie die Datenvariable entlang der y-Achse visualisieren.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
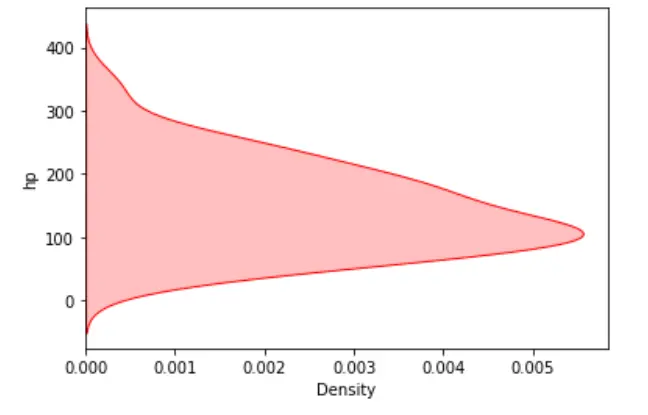
sn.kdeplot(data=dataset, y="hp", shade=True, color="red")
plt.show()
Ausgabe:
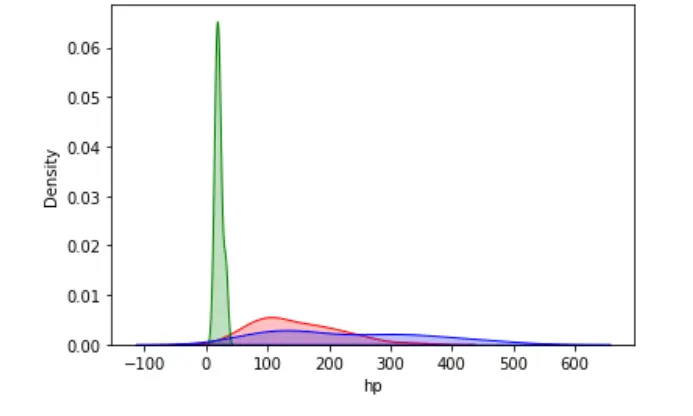
Wir können die Wahrscheinlichkeitsverteilung mehrerer Zielwerte in einem einzigen Diagramm visualisieren.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, x="hp", shade=True, color="red")
sn.kdeplot(data=dataset, x="mpg", shade=True, color="green")
sn.kdeplot(data=dataset, x="disp", shade=True, color="blue")
plt.show()
Ausgabe:
Zweidimensionaler oder bivariater KDE-Plot mit Pandas und Seaborn in Python
Mithilfe der Seaborn- und Pandas-Bibliothek können wir Daten in zweidimensionalen oder bivariaten KDE-Plots visualisieren.
Auf diese Weise können wir die Wahrscheinlichkeitsverteilung einer bestimmten Stichprobe gegenüber mehreren kontinuierlichen Attributen visualisieren. Wir visualisierten die Daten entlang der x- und y-Achse.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg")
plt.show()
Ausgabe:
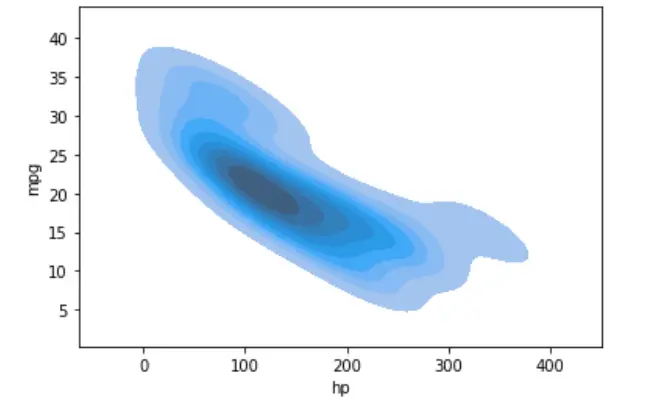
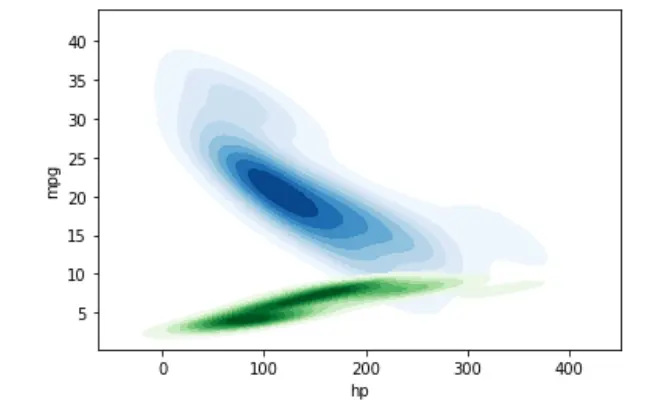
Auf ähnliche Weise können wir die Wahrscheinlichkeitsverteilung mehrerer Stichproben mit einem einzigen KDE-Diagramm darstellen.
Beispielcode:
import seaborn as sn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Read CSV file using pandas
dataset = pd.read_csv(r"C:\\Users\\DELL\\OneDrive\\Desktop\\samplecardataset.csv")
# KDE plotting using seaborn
sn.kdeplot(data=dataset, shade=True, x="hp", y="mpg", cmap="Blues")
sn.kdeplot(data=dataset, shade=True, x="hp", y="cyl", cmap="Greens")
plt.show()
Ausgabe:
Fazit
Wir haben in diesem Tutorial die Verwendung der KDE-Diagrammvisualisierung unter Verwendung der Pandas- und Seaborn-Bibliothek demonstriert. Wir haben gesehen, wie man die Wahrscheinlichkeitsverteilung einzelner und mehrerer Stichproben in einem eindimensionalen KDE-Diagramm visualisiert.
Wir haben diskutiert, wie man den KDE-Plot mit Seaborn und Pandas verwendet, um die zweidimensionalen Daten zu visualisieren.
Verwandter Artikel - Pandas DataFrame
- Wie man Pandas DataFrame-Spaltenüberschriften als Liste erhält
- Pandas DataFrame-Spalte löschen
- Wie man DataFrame-Spalte in Datetime in Pandas konvertiert
- Wie konvertiert man eine Fließkommazahl in eine Ganzzahl in Pandas DataFrame
- Wie man Pandas-DataFrame nach den Werten einer Spalte sortiert
- Wie erhält man das Aggregat der Pandas gruppenweise und sum