Scrape HTML-Tabellen mit BeautifulSoup in einen Datenrahmen
Python verfügt über verschiedene Pakete, mit denen Sie unter Berücksichtigung der Projektanforderungen arbeiten können. Eines davon ist BeautifulSoup, das zum Parsen von HTML- und XML-Dokumenten verwendet wird.
Es erstellt einen Parse-Baum für die geparsten Seiten, den wir verwenden können, um Informationen (Daten) aus HTML zu extrahieren, was für das Web-Scraping von Vorteil ist. Das heutige Tutorial zeigt, wie man mit dem BeautifulSoup-Paket HTML-Tabellen in einen Datenrahmen kratzt.
Verwenden Sie BeautifulSoup, um HTML-Tabellen in einen Datenrahmen zu scrapen
Es ist nicht notwendig, dass wir jedes Mal die geordneten und bereinigten Daten erhalten.
Manchmal benötigen wir die Daten, die auf den Websites verfügbar sind. Dafür müssen wir in der Lage sein, es zu sammeln.
Glücklicherweise hat Pythons BeautifulSoup-Paket die Lösung für uns. Lassen Sie uns lernen, wie wir dieses Paket verwenden können, um Tabellen in einen Datenrahmen zu kratzen.
Zuerst müssen wir dieses Paket auf unserem Computer installieren, um es in unsere Python-Skripte importieren zu können. Wir können den Befehl pip verwenden, um BeautifulSoup auf dem Windows-Betriebssystem zu installieren.
pip install beautifulsoup
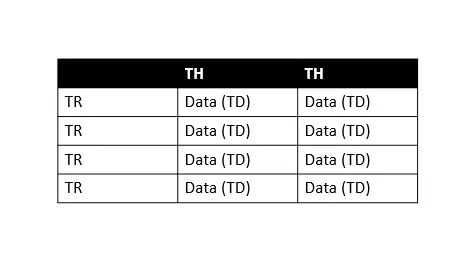
Weitere Informationen finden Sie in dieser Dokumentation. Wir wissen, dass wir mit der Grundstruktur der HTML-Tabelle nicht vertraut sind, was beim Scrapen wichtig ist; Lassen Sie uns das verstehen, um diesem Tutorial zu folgen.
In der obigen Tabelle bedeutet TH Tabellenkopf, TR Tabellenzeile und TD Tabellendaten (wir nennen es Zellen). Wie wir sehen können, enthält jede Tabellenzeile mehrere Tabellendaten, sodass wir leicht über jede Zeile iterieren können, um Informationen zu extrahieren.
Jetzt lernen wir es Schritt für Schritt.
-
Bibliotheken importieren
import requests import pandas as pd from bs4 import BeautifulSoupZuerst müssen wir alle diese Bibliotheken importieren, die Bibliothek
pandaszum Arbeiten mit Datenrahmen,bs4(schöne Suppe) zum Scrapen von Daten und die Bibliothekrequestszum Erstellen von HTTP-Anforderungen mit Python. -
Laden Sie Inhalte von der Webseite herunter
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus" data = requests.get(web_url).text # data # print(data) # print(type(data))Hier speichern wir die benötigte URL in der Variable
web_urlund stellen mit dem Modulrequestseinen HTTP-Request.Wir verwenden
.get()aus dem Modulrequests, um Daten von der angegebenenweb_urlabzurufen, während.textbedeutet, dass wir Daten als Zeichenfolge abrufen möchten.Wenn wir also als
print(type(data))drucken, werden wir sehen, dass wir den HTML-Code der gesamten Seite als String abgerufen haben. Sie können herumspielen, indem Siedata,print(data)undprint(type(data))drucken.All dies befindet sich im obigen Codezaun; Sie können sie auskommentieren und üben.
-
Erstellen Sie das Objekt
BeautifulSoupbeautiful_soup = BeautifulSoup(data, "html.parser") # print(type(beautiful_soup.b))Das Objekt
BeautifulSoup(beautiful_soup) repräsentiert das gesamte geparste Dokument. Wir können also sagen, dass es sich um ein vollständiges Dokument handelt, das wir zu kratzen versuchen.Meistens behandeln wir es als
Tag-Objekt, was auch mit derprint(type(beautiful_soup.b))-Anweisung überprüft werden kann. Jetzt haben wir den vollständigen HTML-Code der erforderlichen Seite.Der nächste Schritt besteht darin, die gewünschte Tabelle herauszufinden. Wir könnten Informationen von der allerersten Tabelle erhalten, aber es besteht die Möglichkeit, dass sich mehrere Tabellen auf derselben Webseite befinden.
Daher ist es wichtig, die erforderliche Tabelle zu finden, die wir kratzen möchten. Wie? Wir können das leicht tun, indem wir den Quellcode untersuchen.
Klicken Sie dazu mit der rechten Maustaste irgendwo auf die gewünschte Webseite und wählen Sie
Inspizieren, drücken Sie Strg+Umschalt+C, um die auszuwählen Elemente (im folgenden Screenshot rot hervorgehoben), können Sie auch das Suchfeld verwenden, um bestimmte Tags zu finden (im folgenden Screenshot grün hervorgehoben).
Wir haben drei Tische; Wie im obigen Screenshot gezeigt (siehe diese Nummer im Suchfeld, grün hervorgehoben), verwenden wir die hervorgehobene Tabelle mit
class="wikitable sortable jquery-tablesorter".Der Punkt ist, warum verwenden wir das Attribut
Klasse, um die Tabelle auszuwählen? Das liegt daran, dass die Tabellen keinen Titel haben, sondern einclass-Attribut. -
Verifizieren Sie Tabellen mit ihren Klassen
print("Classes of Every table:") for table in beautiful_soup.find_all("table"): print(table.get("class"))Ausgang:
Classes of Every table: ['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content'] ['wikitable', 'sortable'] ['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']Hier iterieren wir über alle
<table>-Elemente, um ihre Klassen zu finden, indem wir dasclass-Attribut abrufen. -
Suchen Sie nach den Klassen
wikitableundsortabletables = beautiful_soup.find_all("table") table = beautiful_soup.find("table", class_="wikitable sortable")Zuerst erstellen wir eine Liste aller Tabellen und suchen dann die Tabelle mit den Klassen
wikitableundsortable. -
Erstellen Sie einen Datenrahmen und füllen Sie ihn
df = pd.DataFrame( columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"] ) mylist = [] for table_row in table.tbody.find_all("tr"): table_columns = table_row.find_all("td") if table_columns != []: neighbor = table_columns[0].text.strip() zone = table_columns[1].text.strip() area = table_columns[2].span.contents[0].strip("&0.") population = table_columns[3].span.contents[0].strip("&0.") density = table_columns[4].span.contents[0].strip("&0.") home_count = table_columns[5].span.contents[0].strip("&0.") mylist.append([neighbor, zone, area, population, density, home_count]) df = pd.DataFrame( mylist, columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"], )Hier definieren wir einen Datenrahmen mit den Spalten
Nachbarschaft,Gebiet,Gebiet,Bevölkerung,DichteundHäuser_Anzahl. Dann iterieren wir über die HTML-Tabelle, um Daten abzurufen und den soeben definierten Datenrahmen zu füllen. -
Verwenden Sie
df.head(), um die ersten fünf Dokumente zu druckenprint(df.head())Ausgang:
Neighborhood Zone Area Population Density Homes_count 0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224 1 Aleixo Centro-Sul 618.34 24417 3340.4 6101 2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193 3 Armando Mendes Leste 307.65 33441 9194.86 7402 4 Betânia Sul 52.51 1294 20845.55 3119
Vollständiger Quellcode:
import requests
import pandas as pd
from bs4 import BeautifulSoup
web_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus"
data = requests.get(web_url).text
beautiful_soup = BeautifulSoup(data, "html.parser")
print("Classes of Every table:")
for table in beautiful_soup.find_all("table"):
print(table.get("class"))
tables = beautiful_soup.find_all("table")
table = beautiful_soup.find("table", class_="wikitable sortable")
df = pd.DataFrame(
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"]
)
mylist = []
for table_row in table.tbody.find_all("tr"):
table_columns = table_row.find_all("td")
if table_columns != []:
neighbor = table_columns[0].text.strip()
zone = table_columns[1].text.strip()
area = table_columns[2].span.contents[0].strip("&0.")
population = table_columns[3].span.contents[0].strip("&0.")
density = table_columns[4].span.contents[0].strip("&0.")
home_count = table_columns[5].span.contents[0].strip("&0.")
mylist.append([neighbor, zone, area, population, density, home_count])
df = pd.DataFrame(
mylist,
columns=["Neighborhood", "Zone", "Area", "Population", "Density", "Homes_count"],
)
print(df.head())
Ausgang:
Classes of Every table:
['box-Desatualizado', 'plainlinks', 'metadata', 'ambox', 'ambox-content']
['wikitable', 'sortable']
['nowraplinks', 'collapsible', 'collapsed', 'navbox-inner']
Neighborhood Zone Area Population Density Homes_count
0 Adrianópolis Centro-Sul 248.45 10459 3560.88 3224
1 Aleixo Centro-Sul 618.34 24417 3340.4 6101
2 Alvorada Centro-Oeste 553.18 76392 11681.73 18193
3 Armando Mendes Leste 307.65 33441 9194.86 7402
4 Betânia Sul 52.51 1294 20845.55 3119
