MySQL-Datenbanksynchronisierung
- MySQL-Datenbanksynchronisierung
- Firewall der Quellmaschine konfigurieren
- Quelldatenbank konfigurieren
- Replikationsbenutzer erstellen
- Slave-Server konfigurieren
Dieser Artikel soll zeigen, wie eine Datenbanksynchronisierung für Sicherungs- und Aufzeichnungszwecke erreicht wird.
MySQL-Datenbanksynchronisierung
Beim Umgang mit großen Datenmengen kann es entscheidend sein, Szenarien zu berücksichtigen, in denen die Daten kompromittiert werden könnten.
Der Grund, warum es kompromittiert wurde, kann von vielen Faktoren abhängen, die bei der Entwicklung oder Planung verschiedener Strategien zur Bewältigung dieses speziellen Problems berücksichtigt werden müssen.
Die Entscheidung, Suchmaßnahmen zu implementieren, ist äußerst wichtig; je nach wert der daten kann es einem unternehmen oder einer einrichtung bei einem datenverlust durch einen technischen fehler ohne sicherungsreserven enorme verluste bescheren, da die daten dauerhaft verloren gehen.
Die Lösung
Die Lösung für dieses Problem kann je nach Bedingungen und Einschränkungen variieren. Alles in allem ist einer der häufigsten Ansätze für die Datenbank unten.
- Client/Server-Modell – Anstatt Datenbanken zu verwenden, verwenden Sie Anwendungen, die direkt mit dem Server kommunizieren, um auf Daten zuzugreifen/zu speichern.
- Master/Slave-Modell – Ein Server ist dem Schreiben von Daten (Master) und der andere (es können mehrere sein) ausschließlich dem Lesen der Daten (Slave) zugeordnet.
- Offline-Modell – Führen Sie nach einer festgelegten Zeit die erforderlichen Schritte lokal aus und senden Sie sie an den Server.
In diesem Artikel werden wir über die Implementierung des Master/Slave-Modells sprechen.
Voraussetzungen
- Zwei Maschinen fungieren als Server, auf denen Ubuntu (20.0+) ausgeführt wird. Jeder Computer sollte einen Nicht-Admin-Benutzer und ordnungsgemäß konfigurierte
sudo-Berechtigungen haben. Außerdem müssen die Firewalls mit UFW konfiguriert werden. - MySQL ist auf beiden Rechnern installiert. Vorzugsweise die neueste Version (8.0+).
Firewall der Quellmaschine konfigurieren
Wenn die Firewall auf UFW eingestellt ist, blockiert die Firewall alle eingehenden Verbindungen vom Replikatserver. Um dies zu beheben, führen Sie die folgenden Befehle auf dem Quellcomputer aus.
sudo ufw allow REPLICA_SERVER_IP_ADDR to any port MySQL_PORT
Was bei erfolgreicher Ausführung die Ausgabe zeigt:
Rule Added
Denken Sie daran, dass im folgenden Befehl:
REPLICA_SERVER_IP_ADDR– IP-Adresse des Replica-Servers.MySQL_PORT– Port des MySQL-Servers (Standard ist3306).
Im obigen Befehl fügen wir der UFW eine Regel hinzu, die sie anweist, alle eingehenden Verbindungen zuzulassen, die von der IP REPLICA_SERVER_IP_ADDR zum Port MySQL_PORT kommen.
Quelldatenbank konfigurieren
Einige ihrer Einstellungen müssen optimiert werden, damit die Quelldatenbank mit der Datenreplikation fortfahren kann.
Dazu müssen wir auf die Konfigurationsdatei des MySQL-Servers namens mysqld.cnf zugreifen. Unter Ubuntu 20+ befindet es sich im Verzeichnis /etc/mysql/mysql.conf.d/.
Öffnen Sie diese Datei mit Ihrem bevorzugten Texteditor. Verwenden Sie alternativ den folgenden Befehl:
sudo gedit /etc/mysql/mysql.conf.d/mysqld.cnf
Suchen Sie in der Datei mysql.cnf nach folgender Zeile:
. . .
bind-address = 127.0.0.1
. . .
Die Eigenschaft bind-address bestimmt, wo die Datenbank Verbindungen von 127.0.0.1 akzeptiert, die localhost darstellen; Das bedeutet, dass der Server nur Verbindungsanfragen von der Maschine akzeptiert, auf der der Server derzeit installiert ist.
Um Verbindungen vom Replica-Server zu akzeptieren, müssen wir die Adresse ändern, die der Eigenschaft bind-address gegeben wird. Das Ändern in die IP-Adresse des Quellservers reicht aus.
Nach dem Ändern der IP-Adresse sollte Ihre Datei wie folgt aussehen:
. . .
bind-address = SRC_SERVER_IP_ADDR
. . .
Die SRC_SERVER_IP_ADDR ist die IP-Adresse der Quellmaschine.
Als nächstes müssen wir dem Master eine eindeutige ID zuweisen. Jeder Server ist Teil einer replizierten Umgebung, daher muss jedem Server eine eindeutige ID zugewiesen werden, um sicherzustellen, dass es keine Konflikte zwischen den Servern gibt.
Suchen Sie dazu in der Datei mysql.cnf nach server-id. Das Ergebnis wird wie folgt aussehen:
. . .
# server-id = 1
. . .
Das Zeichen # zeigt an, dass diese Zeile derzeit auskommentiert ist; Löschen Sie das Zeichen und wählen Sie einen ganzzahligen Wert aus, der dem Server zugewiesen werden soll. Nachdem Sie Änderungen vorgenommen haben, sieht die Zeile wie folgt aus:
. . .
server-id = 10
. . .
Suchen Sie danach nach der Direktive log_bin und kommentieren Sie sie aus. Das log_bin muss der Replica-Server lesen, um zu verstehen, wie er die Datenbank replizieren soll.
Nach der Änderung sollte die Zeile wie folgt aussehen:
. . .
log_bin = /var/log/mysql/mysql-bin.log
. . .
Suchen Sie zuletzt nach der Direktive binlog_do_db; Diese Zeile wird ebenfalls auskommentiert, kommentieren Sie sie aus und setzen Sie ihren Wert auf den Namen der Datenbank, die Sie replizieren möchten. Nach der Modifikation sieht es so aus:
. . .
binlog_do_db = DB_NAME
# For multiple DBs
binlog_do_db = DB_NAME_1
binlog_do_db = DB_NAME_2
. . .
Alternativ können Sie mit binlog_ignore_db eine bestimmte Datenbank ausschliessen und den Rest replizieren.
. . .
binlog_ignore_db = DB_NAME_TO_IGNORE
. . .
Nachdem Sie diese Änderungen in mysqld.cnf vorgenommen haben, speichern Sie die Datei und starten Sie den Dienst mysql neu.
Sie können dies mit dem folgenden Befehl tun.
sudo systemctl restart mysql
Replikationsbenutzer erstellen
Der Replikatserver muss einen Benutzernamen und ein Kennwort angeben, um eine Verbindung mit dem Quellserver herzustellen. Replikatserver können eine Verbindung mit jedem Benutzerprofil herstellen, das auf dem Quellcomputer verfügbar ist, aber in diesem Lernprogramm erstellen wir einen dedizierten Benutzer für die Replikation.
Befolgen Sie die Schritte zum Erstellen eines Benutzers für Replikationszwecke.
Führen Sie auf Ihrem Quellcomputer den folgenden Befehl aus:
sudo mysql -u USER -p PASS
Wo:
BENUTZER- Benutzername des BenutzersPASS- Passwort des Benutzers
Innerhalb der MySQL-Eingabeaufforderung können Sie mit dem folgenden Befehl einen neuen Benutzer erstellen:
mysql> CREATE USER 'REPLICA_USER'@'REPLICA_IP' IDENTIFIED WITH mysql_native_password BY 'PASS';
Wo:
REPLICA_USER– Der Benutzername des Benutzers für den Replica-ServerREPLICA_IP– IP-Adresse des ReplikationscomputersPASS- Passwort des Benutzers
Nachdem der Benutzer erfolgreich erstellt wurde, müssen wir ihm die entsprechenden Berechtigungen erteilen. Der Benutzer muss mindestens den REPLICATION SLAVE haben.
Gewähren Sie die Benutzeranwendung mit dem folgenden Befehl:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'REPLICA_USER'@'REPLICA_IP';
Danach müssen wir die Berechtigungen löschen, um den verwendeten Speicher und die Caches mit den Befehlen GRANT und CREATE USER zu löschen.
mysql> FLUSH PRIVILEGES;
Und schließlich müssen wir den Status unserer Datenbank überprüfen und die Lesesperre verwenden, um zu verhindern, dass Schreibvorgänge stattfinden, während die Erfassung des Protokollstatus im Gange ist.
Führen Sie dazu die folgenden Befehle aus:
mysql> FLUSH TABLES WITH READ LOCK;
Überprüfen Sie dann den Status des Servers mit dem folgenden Befehl:
mysql> SHOW MASTER STATUS;
Die Ausgabe wird im folgenden Format zurückgegeben:
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 899 | db | | |
| mysql-bin.000002 | 900 | db2 | | |
+------------------+----------+--------------+------------------+-------------------+
2 rows in set (0.01 sec)
Danach können Sie die gesamte Datenbank mit mysqldump replizieren:
sudo mysqldump -u root db > db.sql
Es wird eine Datei namens new_db.sql generiert, die Sie auf die Slave-Maschine übertragen können, um den Backup-Vorgang abzuschließen.
Wenn die Sicherung abgeschlossen ist, können Sie die Tabellen entsperren.
mysql> UNLOCK TABLES
Slave-Server konfigurieren
Auf dem Slave-Server müssen Sie eine neue Datenbank erstellen, in der die Datenbank repliziert wird. Sie können dies wie folgt tun:
mysql> CREATE DATABASE DATABASE_NAME
Importieren Sie nun den exportierten sqldump von der Quellmaschine.
sudo mysql db < /PATH/db.sql
Sobald die Datenbank in die Slave-Maschine importiert wurde, konfigurieren Sie die Anweisungen in mysqld.cnf wie folgt:
server-id = 11
log_bin = /data/mysql/mysql-bin.log
binlog_do_db = DATABASE_NAME
Nachdem Sie die erforderlichen Änderungen vorgenommen haben, starten Sie den MySQL-Dienst neu.
sudo systemctl restart mysql
Um schließlich die Replikation von Daten vom Server zu starten, führen Sie die folgenden Befehle aus:
Gehen Sie in den MySQL-Eingabeaufforderungen nach der Anmeldung wie folgt vor:
mysql> CHANGE REPLICATION SOURCE TO
mysql> SOURCE_HOST='SRC_SERVER_IP_ADDR',
mysql> SOURCE_USER='REP_USER',
mysql> SOURCE_PASSWORD='PASS',
mysql> SOURCE_LOG_FILE='mysql-bin.000001',
mysql> SOURCE_LOG_POS=899;
Starten Sie schließlich den Slave-Server.
mysql > START REPLICA
Jetzt beginnt der Server mit der Replikation der Änderungen vom Quellserver.
Verwenden Sie den folgenden Befehl, um den Status des Replikatservers anzuzeigen:
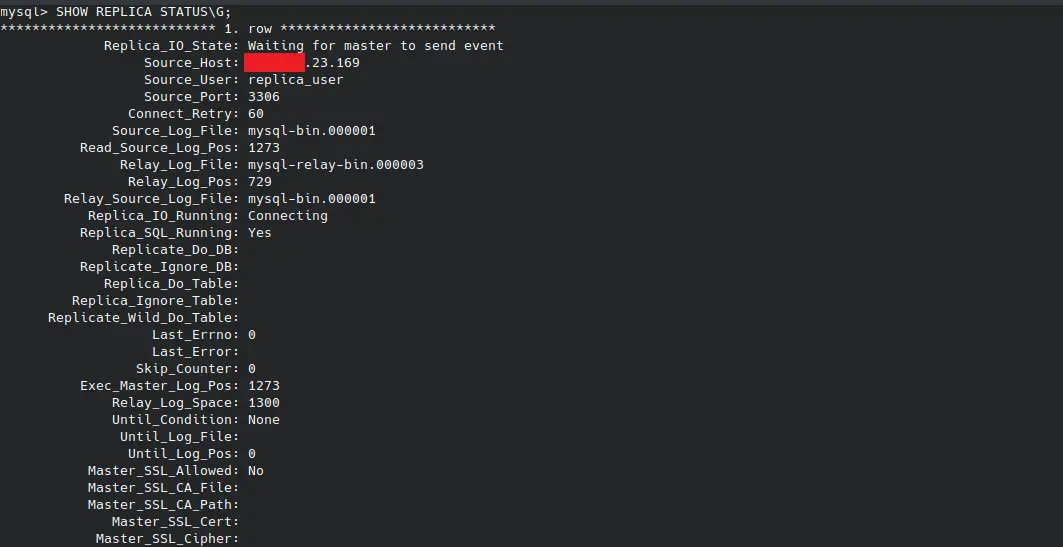
SHOW REPLICA STATUS\G
Das \G formatiert die Ausgabe zur besseren Lesbarkeit neu.
Die Ausgabe des obigen Befehls hat das folgende Format:

Hello! I am Salman Bin Mehmood(Baum), a software developer and I help organizations, address complex problems. My expertise lies within back-end, data science and machine learning. I am a lifelong learner, currently working on metaverse, and enrolled in a course building an AI application with python. I love solving problems and developing bug-free software for people. I write content related to python and hot Technologies.
LinkedIn