Scipy scipy.optimize.curve_fit Methode
-
Syntax von
scipy.optimize.curve_fit(): -
Beispielcodes:
scipy.optimize.curve_fit()Methode zum Anpassen einer geraden Linie an unsere Daten (linearer Modellausdruck) -
Beispielcode:
scipy.optimize.curve_fit()Methode zum Anpassen der Exponentialkurve an unsere Daten (exponentieller Modellausdruck)
Die Python-Scipy-Funktion scipy.optimize.curve_fit() wird verwendet, um die am besten passenden Parameter mithilfe einer Anpassung nach der Methode der kleinsten Quadrate zu finden. Die Methode curve_fit passt unser Modell an die Daten an.
Die Kurvenanpassung ist wesentlich, um den optimalen Parametersatz für die definierte Funktion zu finden, der am besten zu dem bereitgestellten Satz von Beobachtungen passt.
Syntax von scipy.optimize.curve_fit():
scipy.optimize.curve_fit(f, xdata, ydata, sigma=None, p0=None)
Parameter
f |
Es ist die Modellfunktion. Akzeptiert eine unabhängige Variable als erstes Argument und die anzupassenden Parameter als separate verbleibende Argumente. |
xdata |
Array-artig. Unabhängige Variable oder Eingabe für die Funktion. |
ydata |
Array-artig. Abhängige Variable. Die Ausgabe der Funktion. |
sigma |
Optionaler Wert. Es sind die geschätzten Unsicherheiten in den Daten. |
p0 |
Erste Vermutung für die Parameter. Die Kurvenanpassung sollte wissen, wo die Jagd beginnen sollte, was vernünftige Werte für die Parameter sind. |
Zurückkehren
Es gibt zwei Werte zurück:
popt: Array-artig. Es enthält optimale Werte für die Modellfunktion. Enthält intern Anpassungsergebnisse fürslopeund Anpassungsergebnisse fürintercept.p-cov: Kovarianz, die Unsicherheiten im Anpassungsergebnis bezeichnet.
Beispielcodes: scipy.optimize.curve_fit() Methode zum Anpassen einer geraden Linie an unsere Daten (linearer Modellausdruck)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * x + b
x = np.linspace(start=-50, stop=10, num=40)
y = function(x, 6, 2)
np.random.seed(6)
noise = 20 * np.random.normal(size=y.size)
y = y + noise
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), 30, 5)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()

Ausgabe:
Estimated value of a : 5.859050240780936
Estimated value of b : 1.172416121927438
In diesem Beispiel erzeugen wir zuerst einen Datensatz mit 40 Punkten mit der Gleichung y = 6*x+2. Dann fügen wir etwas Gaußsches Rauschen zu den y-Werten des Datensatzes hinzu, damit er realistischer aussieht. Nun schätzen wir die Parameter a und b der zugrunde liegenden Gleichung y=a*x+b, die den Datensatz mit der Methode scipy.optimize.curve_fit() generiert. Die grünen Punkte im Diagramm stellen die tatsächlichen Datenpunkte des Datensatzes dar, und die rote Linie stellt die Kurve dar, die mit der Methode scipy.optimize.curve_fit() an den Datensatz angepasst wurde.
Schließlich können wir sehen, dass die Werte von a und b, die mit der Methode scipy.optimize.curve_fit()geschätzt wurden, 5.859 bzw. 1.172 sind, was ziemlich nahe an den tatsächlichen Werten 6 und 2.
Beispielcode: scipy.optimize.curve_fit() Methode zum Anpassen der Exponentialkurve an unsere Daten (exponentieller Modellausdruck)
import numpy as np
import matplotlib.pyplot as plt
import scipy
from scipy import optimize
def function(x, a, b):
return a * np.exp(b * x)
x = np.linspace(10, 30, 40)
y = function(x, 0.5, 0.3)
print(y)
noise = 100 * np.random.normal(size=y.size)
y = y + noise
print(y)
popt, cov = scipy.optimize.curve_fit(function, x, y)
a, b = popt
x_new_value = np.arange(min(x), max(x), 1)
y_new_value = function(x_new_value, a, b)
plt.scatter(x, y, color="green")
plt.plot(x_new_value, y_new_value, color="red")
plt.xlabel("X")
plt.ylabel("Y")
print("Estimated value of a : " + str(a))
print("Estimated value of b : " + str(b))
plt.show()

Ausgabe:
Estimated value of a : 0.5109620054206334
Estimated value of b : 0.2997005016319089
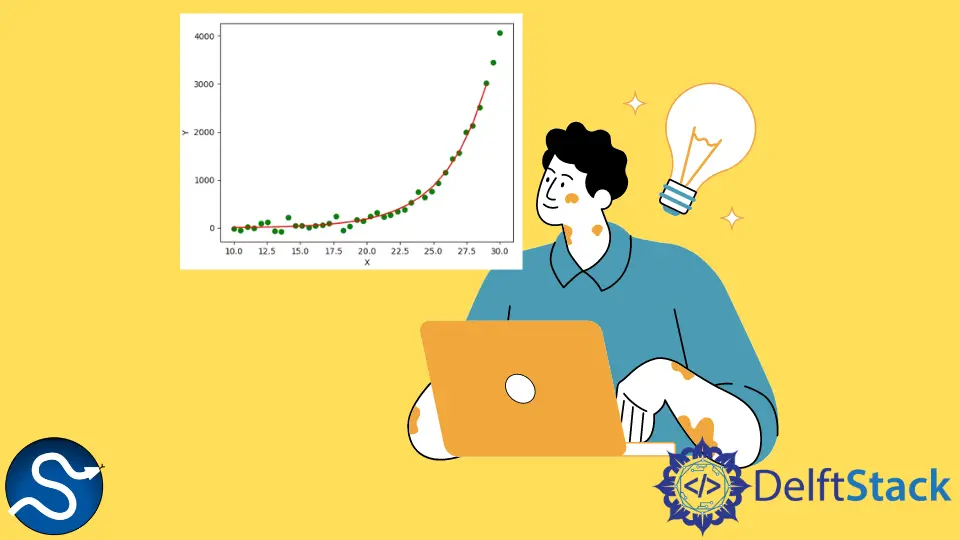
In diesem Beispiel generieren wir zunächst einen Datensatz mit 40 Punkten mit der Gleichung y = 0.5*x^0.3. Dann fügen wir etwas Gaußsches Rauschen zu den y-Werten des Datensatzes hinzu, um ihn realistischer zu machen. Nun schätzen wir die Parameter a und b der zugrunde liegenden Gleichung y = a*x^b, die den Datensatz mit der Methode scipy.optimize.curve_fit() generiert. Die grünen Punkte im Diagramm stellen die tatsächlichen Datenpunkte des Datensatzes dar, und die rote Linie stellt die Kurve dar, die mit der Methode scipy.optimize.curve_fit() an den Datensatz angepasst wurde.
Schließlich können wir sehen, dass die mit der Methode scipy.optimize.curve_fit()geschätzten Werte von a und b 0.5109 bzw. 0.299 sind, was ziemlich nahe an den tatsächlichen Werten 0.5 und 0.3.
Auf diese Weise können wir mit der Methode scipy.optimize.curve_fit() die zugrunde liegende Gleichung gegebener Datenpunkte ermitteln.

Suraj Joshi is a backend software engineer at Matrice.ai.
LinkedIn