Python Pandas pandas.pivot_table() Funktion
-
Syntax der Funktion
pandas.pivot_table() -
Beispiel-Codes:
pandas.pivot_table() -
Beispielcodes:
pandas.pivot_table()zur Angabe mehrerer Aggregatfunktionen -
Beispielcodes:
pandas.pivot_table()zur Verwendung des Parametersmargins
Die Python Pandas pandas.pivot_table() Funktion vermeidet die Wiederholung von Daten des DataFrame. Sie fasst die Daten zusammen und wendet verschiedene Aggregatfunktionen auf die Daten an.
Syntax der Funktion pandas.pivot_table()
pandas.pivot_table(
data,
values=None,
index=None,
columns=None,
aggfunc="mean",
fill_value=None,
margins=False,
dropna=True,
margins_name="All",
observed=False,
)
Parameter
Diese Funktion hat mehrere Parameter. Die Standardwerte aller Parameter sind oben erwähnt.
data |
Es ist der DataFrame, aus dem wir die wiederholten Daten entfernen wollen. |
values |
Sie stellt die zu aggregierende Spalte dar. |
index |
Es ist eine column, ein grouper, ein Array oder eine Liste. Es repräsentiert die Datenspalte, die wir als Index, d.h. als Zeilen, haben wollen. |
columns |
Es ist eine column, ein grouper, ein Array oder eine Liste. Es repräsentiert die Datenspalte, die wir als Spalten in unserer Ausgabepivot-Tabelle haben wollen. |
aggfunc |
Es ist eine Funktion, eine Liste von Funktionen oder ein dictionary. Sie stellt die aggregierte Funktion dar, die auf die Daten angewendet wird. Wenn eine Liste von Aggregatfunktionen übergeben wird, dann gibt es für jede Aggregatfunktion in der resultierenden Tabelle eine Spalte mit dem Spaltennamen ganz oben. |
fill_value |
Es ist ein Skalar. Er repräsentiert den Wert, der die fehlenden Werte in der Ausgabetabelle ersetzt. |
margins |
Es ist ein boolescher Wert. Er stellt die Zeile und Spalte dar, die nach der Bildung der Summe der jeweiligen Zeile und Spalte erzeugt werden. |
dropna |
Es ist ein boolescher Wert. Er eliminiert die Spalten, deren Werte NaN sind, aus der Ausgabetabelle. |
margins_name |
Es ist eine Zeichenkette. Sie repräsentiert den Namen der generierten Zeile und Spalte, wenn der Wert von margins True ist. |
observed |
Es ist ein boolescher Wert. Wenn ein Zackenbarsch kategorisch ist, gilt dieser Parameter. Wenn er True ist, zeigt er die beobachteten Werte für kategorische Zackenbarsche an. Wenn er False ist, zeigt er alle Werte für kategorische Zackenbarsche an. |
Zurück
Es gibt den zusammengefassten DataFrame zurück.
Beispiel-Codes: pandas.pivot_table()
Lassen Sie uns tiefer in diese Funktion eindringen, indem wir sie implementieren.
import pandas as pd
dataframe = pd.DataFrame({
"Name":
["Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan"],
"Date":
["03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019"],
"Science Marks":
[10,
2,
4,
6,
8,
9,
1,
10]
})
print(dataframe)
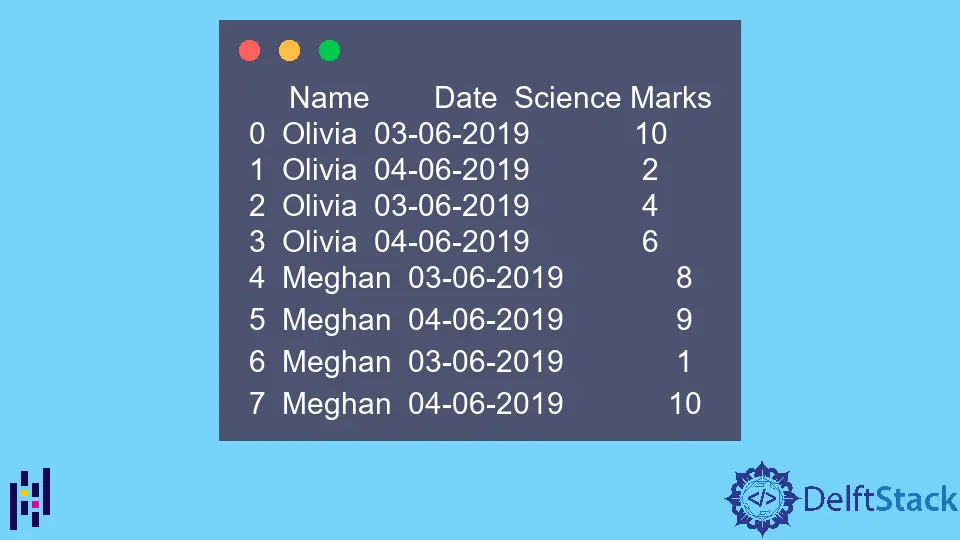
Das Beispiel DataFrame ist,
Name Date Science Marks
0 Olivia 03-06-2019 10
1 Olivia 04-06-2019 2
2 Olivia 03-06-2019 4
3 Olivia 04-06-2019 6
4 Meghan 03-06-2019 8
5 Meghan 04-06-2019 9
6 Meghan 03-06-2019 1
7 Meghan 04-06-2019 10
Beachten Sie, dass die obigen Daten denselben Wert in einer Spalte mehrfach enthalten. Diese pivot_table Funktion fasst diese Daten zusammen.
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(dataframe, index="Name", columns="Date")
print(pivotTable)
Ausgabe:
Science Marks
Date 03-06-2019 04-06-2019
Name
Meghan 4.5 9.5
Olivia 7.0 4.0
Hier haben wir die Spalte Name als Index und die Spalte Date als Spalte gewählt. Die Funktion hat das Ergebnis auf der Grundlage der Standardparameter erzeugt. Die voreingestellte Aggregatfunktion mean() hat den Mittelwert der Werte berechnet.
Beispielcodes: pandas.pivot_table() zur Angabe mehrerer Aggregatfunktionen
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"]
)
print(pivotTable)
Ausgabe:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 03-06-2019 04-06-2019
Name
Meghan 9 19 2 2
Olivia 14 8 2 2
Wir haben zwei Aggregatfunktionen verwendet. Die Spalten dieser Funktionen werden separat generiert.
Beispielcodes: pandas.pivot_table() zur Verwendung des Parameters margins
import pandas as pd
dataframe = pd.DataFrame(
{
"Name": [
"Olivia",
"Olivia",
"Olivia",
"Olivia",
"Meghan",
"Meghan",
"Meghan",
"Meghan",
],
"Date": [
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
"03-06-2019",
"04-06-2019",
],
"Science Marks": [10, 2, 4, 6, 8, 9, 1, 10],
}
)
pivotTable = pd.pivot_table(
dataframe, index="Name", columns="Date", aggfunc=["sum", "count"], margins=True
)
print(pivotTable)
Ausgabe:
sum count
Science Marks Science Marks
Date 03-06-2019 04-06-2019 All 03-06-2019 04-06-2019 All
Name
Meghan 9 19 28 2 2 4
Olivia 14 8 22 2 2 4
All 23 27 50 4 4 8
Der Parameter margins hat eine neue Zeile mit dem Namen All und eine neue Spalte mit dem Namen All erzeugt, die jeweils die Summe der Zeile und der Spalte anzeigen.